Web 多媒体开发中的二进制数据处理

在终端多媒体技术领域,音视频数据一般以二进制格式进行呈现和编辑。例如视频播放时的解封装、视频剪辑时的片段剪切、视频上传时的文件读取等等。一个比较通用的问题是:在 Web 平台上,如何读取奇数长度的字节数据,以及如何从左到右按位读取数据?
要理解这个问题,得先看看二进制数据在 Web 平台上是如何表达以及可以如何处理。
二进制与位运算
首先来温习一下大学计算机组成的相关知识点。
进制转换
二进制就是通过 0 和 1 来表示所有的数。它和十进制的换算关系是:
| 十进制 | 二进制 | 位数 |
|---|---|---|
| 0 | 00000000 | 1 |
| 1 | 00000001 | 1 |
| 2 | 00000010 | 2 |
| 3 | 00000011 | 2 |
| 4 | 00000100 | 3 |
| 7 | 00000111 | 3 |
| 15 | 00001111 | 4 |
| 31 | 00011111 | 5 |
| 63 | 00111111 | 6 |
| 127 | 01111111 | 7 |
| 255 | 11111111 | 8 |
可见,不同的二进制位数能表示的十进制数值是有限的。以正整数为例,二进制位数与最大十进制数的关系是:
MaxNumber = 2**bit - 1;
255 = 2**8 - 1;即代表在二进制里有 8 位时能表示的无符号整型范围为 0 到 255。同理有符号整型范围则为 -128 到 127。
在现代计算机中普遍定义 8 位(bit) = 1 字节(byte) 。
2-补码表示法
一个基本的问题:负数在计算机中如何表示?举例来说,+8 在计算机中表示为二进制的 1000,那么 -8 怎么表示呢?
很容易想到,可以将一个二进制位(bit)专门规定为符号位,它等于 0 时就表示正数,等于 1 时就表示负数。比如,在 8 位机中,规定每个字节的最高位为符号位。那么,+8 就是 00001000,而 -8 则是 10001000。
但实际上,计算机内部采用2的补码(Two’s Complement)表示负数。它是一种数值的转换方法,要分二步完成:
- 每一个二进制位都取相反值,
0变成1,1变成0。比如,00001000的相反值就是11110111(1的补码表示法)。 - 第二步,将上一步得到的值加
1。11110111就变成11111000。
所以 00001000的 2-补码就是 11111000。也就是说 -8 在计算机(8位机)中用 11111000 表示。
为什么要用 2-补码表示法呢?
首先要明确一点,计算机内部用什么方式表示负数,其实是无所谓的。只要能够保持一一对应的关系,就可以用任意方式表示负数。所以既然可以任意选择,那么理应选择一种最方便的方式。2-补码就是最方便的方式。它的便利体现在,所有的加法运算可以使用同一种电路完成。
还是以 -8 作为例子。假定有两种表示方法。一种是直觉表示法,即 10001000;另一种是 2-补码表示法,即 11111000。请问哪一种表示法在加法运算中更方便?随便写一个计算式,16 + (-8) = ? 看看:
16 的二进制表示是 00010000,所以用直觉表示法,加法就要写成:
00010000
+10001000
---------
10011000可以看到如果按照正常的加法规则,就会得到 10011000 的结果,转成十进制就是 -24。显然这是错误的答案。也就是说,在这种情况下,正常的加法规则不适用于正数与负数的加法,因此必须制定两套运算规则,一套用于正数加正数,还有一套用于正数加负数。从电路上说,就是必须为加法运算做两种电路。
现在,再来看 2-补码表示法。
00010000
+11111000
---------
100001000可以看到按照正常的加法规则,得到的结果是 100001000。注意,这是一个 9 位的二进制数。我们已经假定这是一台 8 位机,因此最高的第 9 位是一个溢出位,会被自动舍去。所以,结果就变成了 00001000,转成十进制正好是8,也就是 16 + (-8) 的正确答案。这说明了,2-补码表示法可以将加法运算规则,扩展到整个整数集,从而用一套电路就可以实现全部整数的加法。
位运算符
Javascript 中的位运算符将它的操作数视为 32 位元的二进制串。例如:十进制数字 9 用二进制表示为 1001,位运算符就是在这个二进制表示上执行运算,但是返回结果是标准的 JavaScript 数值。
下表总结了 JavaScript 的位运算符。
| 运算符 | 名称 | 示例 | 描述 |
|---|---|---|---|
& | 与 | a & b | 在 a,b 的位表示中,每一个对应的位,都为 1 则返回 1,否则返回 0 |
/ | 或 | a / b | 在 a,b 的位表示中,每一个对应的位,只要有一个为 1 则返回 1,否则返回 0 |
^ | 异或 | a ^ b | 在 a,b 的位表示中,每一个对应的位,两个不相同则返回 1,相同则返回 0 |
~ | 非 | ~ a | 反转被操作数的位 |
<< | 左移 | a << b | 将 a 的二进制串向左移动 b 位,左边移出的几位被丢弃。右边多出的空位由 0 补齐 |
>> | 算术右移(带符号右移) | a >> b | 把 a 的二进制表示向右移动 b 位,右边移出位被抛弃。左边多出的空位由原值的最左边数字补齐 |
>>> | 无符号右移(补零右移) | a >>> b | 把 a 的二进制表示向右移动 b 位,右边移出位被抛弃。左边多出的空位由 0 补齐 |
在 ATA 的 Markdwon 表格里无法使用
|,所以上面用/代替了。下同。
这些位运算法可以分为两种:位逻辑运算符和移位运算符。
位逻辑运算符
概念上来讲,位逻辑运算符工作流程如下:
-
操作数被转换为 32bit 整数,以位序列(0 和 1 组成)表示。若超过 32bits,则取低位 32bit,如下所示:
Before: 11100110111110100000000000000110000000000001 After: 10100000000000000110000000000001 -
第一个操作数的每一位都与第二个操作数的对应位组对:第一位对应第一位,第二位对应第二位,以此类推。
-
运算符被应用到每一对“位”上,最终的运算结果由每一对“位”的运算结果组合起来。
例如,十进制数 9 的二进制表示是 1001,十进制数 15 的二进制表示是 1111。因此,当位运算符应用到这两个值时,结果如下:
| 表达式 | 二进制描述 | 结果 |
|---|---|---|
15 & 9 | 1111 & 1001 = 1001 | 9 |
15 / 9 | 1111 / 1001 = 1111 | 15 |
15 ^ 9 | 1111 ^ 1001 = 0110 | 6 |
~9 | ~ 0000 0000 … 0000 1001 = 1111 1111 … 1111 0110 | -10 |
注意:位运算符“非”将所有的 32 位取反,而值的最高位 (最左边的一位) 为 1 则表示负数 (2-补码表示法)。再来看一个示例:
- 表达式:
~15 - 二进制描述:
~0000 0000 0000 0000 0000 0000 0000 1111 - 二进制结果:
=1111 1111 1111 1111 1111 1111 1111 0000 - 2-补码表示法:
-16
移位运算符
移位运算符带两个操作数:第一个是待移位的数,第二个是指定第一个数要被移多少位的数。移位的方向由运算符来控制。
移位运算符把操作数转为 32bit 整数,然后得出一个与待移位数相同种类的值。
| 表达式 | 二进制描述 | 结果 |
|---|---|---|
9 << 2 | 9 的二进制表示是 1001,移位 2 比特向左变为 100100 | 36 |
9 >> 2 | 移位 2 比特向右变为 0010 | 2 |
-9 >> 2 | -9 的2-补码表示法是 1111 1111 ... 1111 0111,移位 2 比特向右变为 1111 1111 ... 1111 1101 | -3 |
19 >>> 2 | 19 的二进制表示是 10011,移位 2 比特向右变为 100 | 4 |
-19 >>> 2 | -19 的2-补码表示法是 1111 1111 ... 1110 1101,移位 2 比特向右变为 0011 111 ... 1111 1011 | 1073741819 |
Javascript 中的数字
为了能够以 Javascript 处理数据,还需要了解 Javascript 中的数字的表示方法。
类型
在现代 JavaScript 中,数字(number)有两种类型:
- JavaScript 中的常规数字以 64 位的格式 IEEE-754 存储,也被称为“双精度浮点数”。
- BigInt 用于表示任意长度的整数。
在下面的二进制数据缓冲区的类数组视图(TypedArray)中可以看到不同子类型能够存储的数值范围是不一样的。这里我将数字进行一步划分为以下几种:
| 类型 | 描述 | 示例 |
|---|---|---|
| Int | 有符号整型 | 1 |
| Uint | 无符号整型 | -1 |
| Float | IEEE 浮点数 | 3.14159265359 |
| BigInt | 大整数 | 9007199254740991n |
这还不够精细,为了能够更好地使用计算机存储所有的数字类型,可以使用更多的字节大小作为基础单位:
| 类型 | 值范围 | 字节大小 | 描述 | 等价的 C 类型 |
|---|---|---|---|---|
| Int8 | -128 到 127 | 1 | 8 位有符号整型 | signed char |
| Uint8 | 0 到 255 | 1 | 8 位无符号整型 | unsigned char |
| Uint16 | 0 到 65535 | 2 | 16 位无符号整型 | unsigned short |
| Float32 | -3.4E38 到 3.4E38 | 4 | 32 位 IEEE 浮点数 | float |
| Float64 | -1.8E308 到 1.8E308 | 8 | 64 位 IEEE 浮点数 | double |
| BigUint64 | 0 到 2**64 - 1 | 8 | 64 位无符号整型 | unsigned long |
除此之外还有 Int16、Int32、BigInt64、Uint32,这里不一一概述。
极大和极小数的表示
假如需要表示 10 亿。显然可以这样写:
const billion = 1000000000;其实还可以使用下划线 _ 作为分隔符:
const billion = 1_000_000_000;这里的下划线 _ 扮演了“语法糖”的角色,使得数字具有更强的可读性。JavaScript 引擎会直接忽略数字之间的 _,所以 上面两个例子其实是一样的。
但在现实生活中,我们通常会尽量避免写带一长串零的数。在 JavaScript 中 可以通过在数字后面附加字母 “e” 并指定零的个数来缩短数字:
const billion = 1e9; // 10 亿,字面意思:数字 1 后面跟 9 个 0
alert( 7.3e9 ); // 73 亿(与 7300000000 和 7_300_000_000 相同)换句话说,e 把数字乘以 1 后面跟着给定数量的 0 的数字:
1e3 === 1 * 1000; // e3 表示 *1000
1.23e6 === 1.23 * 1000000; // e6 表示 *1000000现在来写一些非常小的数字。例如,1 微秒(百万分之一秒):
const mcs = 0.000001;就像以前一样,可以使用 “e” 来完成。如果想避免显式地写零,可以这样写:
const mcs = 1e-6; // 1 的左边有 6 个 0如果数一下 0.000001 中的 0 的个数,是 6 个。所以自然是 1e-6。
换句话说,e 后面的负数表示除以 1 后面跟着给定数量的 0 的数字:
// -3 除以 1 后面跟着 3 个 0 的数字
1e-3 === 1 / 1000; // 0.001
// -6 除以 1 后面跟着 6 个 0 的数字
1.23e-6 === 1.23 / 1000000; // 0.00000123
// 一个更大一点的数字的示例
1234e-2 === 1234 / 100; // 12.34,小数点移动两次其他进制的数字表示
| 进制 | 前缀 | 示例 |
|---|---|---|
| 十六进制 | 0x | 0xff == 255 |
| 二进制 | 0b | 0b11111111 == 255 |
| 八进制 | 0o | 0o377 == 255 |
方法 num.toString(base) 返回在给定 base 进制数字系统中 num 的字符串表示形式。举个例子:
const num = 255;
num.toString(16); // ff
num.toString(2); // 11111111base 的范围可以从 2 到 36。默认情况下是 10。
BigInt 的表示
BigInt 是一种特殊的数字类型,它提供了对任意长度整数的支持。
创建 bigint 的方式有两种:在一个整数字面量后面加 n 或者调用 BigInt 函数,该函数从字符串、数字等中生成 bigint。
const bigint = 1234567890123456789012345678901234567890n;
const sameBigint = BigInt("1234567890123456789012345678901234567890");
const bigintFromNumber = BigInt(10); // 与 10n 相同Javascript 中的二进制数据
在 JavaScript 中有很多种二进制数据格式,例如 ArrayBuffer,Uint8Array,DataView,Blob,File 等。这里我们只看基础的几个。
ArrayBuffer
最基本的二进制对象是 ArrayBuffer —— 对固定长度的连续内存空间的引用,可以这样创建它:
const buffer = new ArrayBuffer(16); // 入参是要创建的数组缓冲区的大小(以字节为单位)它会分配一个 16 字节的连续内存空间,并用 0 进行预填充。
console.log(buffer.byteLength); // 16ArrayBuffer 与 Array 没有什么共同之处:
- 它的长度是固定的,无法增加或减少它的长度;
- 它正好占用了内存中的那么多空间;
- 要访问单个字节,需要另一个“视图”对象,而不是
buffer[index]。
ArrayBuffer 是一个内存区域。它里面存储了什么无从判断,只是一个原始的字节序列。如要操作 ArrayBuffer 则需要使用“视图”对象。
视图对象本身并不存储任何东西。它是一副“眼镜”,透过它来解释存储在 ArrayBuffer 中的字节。视图对象有 TypedArray 和 DataView 两类,下面会介绍到它们。
例如上面的示例中, ArrayBuffer 存放了 16 个字节的数据。如果以 Uint8 的形式读取,会把 16 个字节数据分到每一个元素上(因为 Uint8 单个元素字节大小是 1),长度即为 16。以 Uint16 的方式读取,长度为 8。依次类推:
const view = new Uint8Array(buffer);
view.length; // 16
const view = new Uint16Array(buffer);
view.length; // 8,存储了 8 个整数
view.byteLength; // 16,字节中的大小TypedArray
ArrayBuffer 是核心对象,是所有的基础,是原始的二进制数据。但是如果要写入值或遍历它,基本上几乎所有操作 —— 必须使用视图(view)。所有类型化视图(Uint8Array,Uint32Array 等)的通用术语是 TypedArray。它们共享同一方法和属性集。
Javascript 中没有称为 TypedArray 的全局变量,也没有直接可用的 TypedArray 构造函数。但是有很多其值是指定元素类型的类型化数组构造函数,例如 Int8Array、Uint8Array、Float32Array 等。它们都是 TypedArray 的子类。
使用语法:
new TypedArray(buffer, [byteOffset], [length]);
new TypedArray(length);
new TypedArray(typedArray);构造函数的入参为指定类型化数组的长度。其中 TypedArray 是一个具体子类的构造函数。例如:
const typedArray1 = new Int8Array(8);
typedArray1[0] = 32;
typedArray1[8] = 32; // 超过长度,不会生效
const typedArray2 = new Int8Array(typedArray1);
typedArray2[1] = 42;
console.log(typedArray1);
// expected output: Int8Array [32, 0, 0, 0, 0, 0, 0, 0]
console.log(typedArray2);
// expected output: Int8Array [32, 42, 0, 0, 0, 0, 0, 0]可以直接创建一个 TypedArray,而无需使用 ArrayBuffer。但是,TypedArray 离不开底层的 ArrayBuffer,因此创建 TypedArray 时都会自动创建 ArrayBuffer。如果要访问底层的 ArrayBuffer,那么在 TypedArray 中有如下的属性:
arr.buffer—— 引用ArrayBuffer。arr.byteLength——ArrayBuffer的长度。
因此总是可以从一个 TypedArray 转到另一个:
const arr8 = new Uint8Array([0, 1, 2, 3]);
// 同一数据的另一个视图
const arr16 = new Uint16Array(arr8.buffer);越界行为
如果尝试将越界值写入类型化数组会出现什么情况?不会报错。但是多余的位会被切除。
例如尝试将 256 放入 Uint8Array。256 的二进制格式是 100000000(9 位),但 Uint8Array 每个值只有 8 位,因此可用范围为 0 到 255。对于更大的数字,仅存储最右边的(低位有效)8 位,其余部分被切除:

因此结果是 0。
257 的二进制格式是 100000001(9 位),最右边的 8 位会被存储:

因此数组中会是 1。
换句话说,该数字对 2**8 取模的结果被保存了下来:
let uint8array = new Uint8Array(16);
let num = 256;
alert(num.toString(2)); // 100000000(二进制表示)
uint8array[0] = 256;
uint8array[1] = 257;
console.log(uint8array[0]); // 0
console.log(uint8array[1]); // 1DataView
虽然 ArrayBuffer 可以用 TypedArray 的形式读取和编辑,但存在多种类型依次读取的方式则使用 DataView 更为方便。
DataView 提供了以不同类型的编辑和读取方式,其 API 定义如下:
// constructor
new DataView(buffer, byteOffset, byteLength);
// set
dataview.setUint8(byteOffset, value [, littleEndian]);
// get
dataview.getUint8(byteOffset);通过一个示例来了解下如何使用 DataView:
const buffer = new ArrayBuffer(8);
const dataview = new DataView(buffer);
// 从 DataView 起始位置以 byte 为计数的指定偏移量 (byteOffset) 处储存一个 8-bit 数
dataview.setUint8(0, 1); // [1, 0, 0, 0, 0, 0, 0, 0]
dataview.setUint16(1, 2); // [1, 0, 2, 0, 0, 0, 0, 0]
dataview.setUint32(3, 3); // [1, 0, 2, 0, 0, 0, 3, 0]下图显示了以 Unit8 进行读取时数据的变化情况:new Uint8Array(buf)

setUint8(0, 1): 从第 1 个字节位置处写入 1 个字节,值是 1setUint16(1, 2): 从第 2 个字节位置处写入 2 个字节,值是 2setUint32(3, 3): 从第 4 个字节位置处写入 4 个字节,值是 3
字节序
需要多个字节来表示的数值,在存储时其字节在内存中的相对顺序依据平台架构的不同而不同。来看一个示例:
const buffer = new ArrayBuffer(8);
const dataview = new DataView(buffer);
dataview.setUint16(0, 3);
dataview.setUint16(2, 5);
dataview.setUint16(4, 2);
dataview.setUint16(6, 7);假设通过 new Uint8Array(buffer) 去读,结果将会是:
[0, 3, 0, 5, 0, 2, 0, 7]通过 new Uint16Array(buffer) 去读,输出的是:
[768, 1280, 512, 1792]结果有些出人意料。这是因为 Uint16Array 使用系统字节序,现在大部分需占用多个字节的数字排序方式是 little-endian(小字节序、低字节序,即低位字节排放在内存的低地址端,高位字节排放在内存的高地址端),所有的英特尔处理器都使用 little-endian。little-endian 的意思是使用低位储存更重要的信息。因此,Uint16Array 进行读取的时候其二进制数据生成逻辑是:
// 先看 Unit8 的表示:高位字节排放在内存的高地址端
则其十进制 = [3, 0, 5, 0, 2, 0, 7, 0]
转化为二进制则是 = [00000011, 00000000, 00000101, 00000000, 00000010, 00000000, 01110000, 00000000]
// Unit16 表示:将 Unit8 的字节值两两合并
则Unit16的二进制是 = [0000001100000000, 0000010100000000, 0000001000000000, 011100000000]
即十进制为 = [768, 1280, 512, 1792]因此 new Uint16Array(buffer)[0] === 768。而使用 DataView 时则不用考虑不同平台的字节序问题:
dataview.getUnit16(0) === 3
dataview.getUnit16(2) === 5同时如果想指定使用小字节序,就可以使用 set 方法的第三个参数:
const buffer = new ArrayBuffer(8);
new DataView(buffer).setInt16(0, 3, true /* littleEndian */);
new Int16Array(buffer)[0] === 3;64 位整数值
可以从 canIuse 官网中看到 getBigUint64 和 getUint32 相比,前者的浏览器兼容性覆盖度较低:
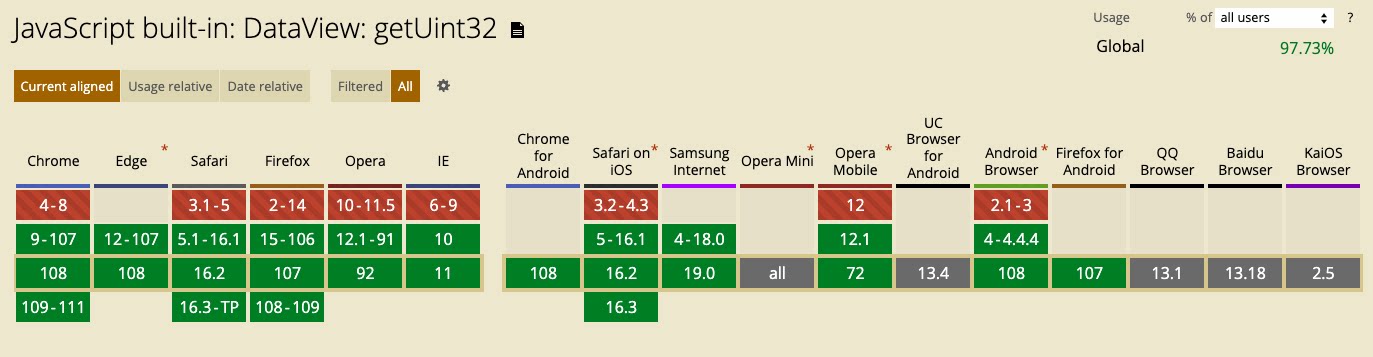
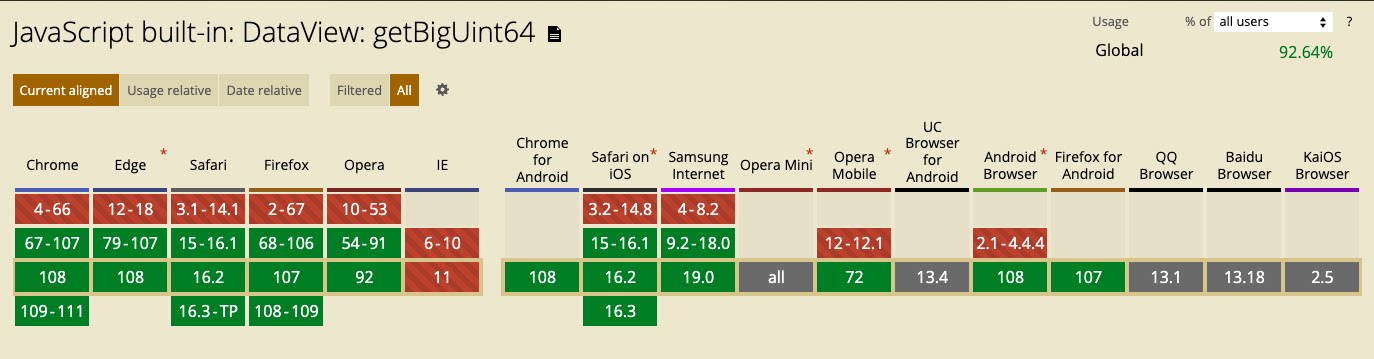
某些浏览器不支持 getBigUint64() 和 getBigInt64(),因此,要在代码中启用跨浏览器的 64 位操作可以实现自己的 getUint64() 函数,以获得精度达到 Number.MAX_SAFE_INTEGER 的值:这足够使用了。
function getUint64(dataview, byteOffset) {
// 将 64 位的数字拆分位两个 32 位(4 字节)的部分
const left = dataview.getUint32(byteOffset);
const right = dataview.getUint32(byteOffset + 4);
// 将两个 32 位的值组合在一起
const combined = ((2**8)**4)*left + right;
if (!Number.isSafeInteger(combined)) {
console.warn(combined, '超过 MAX_SAFE_INTEGER。可能存在精度丢失。');
}
return combined;
}其中关键的实现公式是:
const combined = ((2**8)**byteLength)*left + right;实现原理:
const buffer = new ArrayBuffer(8);
const dataview = new DataView(buffer);
dataview.setUint16(0, 257);
// 即:
new Uint16Array(buffer);
// 十进制 = [257, 0, 0, 0]
// 二进制 = [0000000100000001, ...]
new Uint8Array(buffer);
// 二进制 = [00000001, 00000001, ...]
// 十进制 = [1, 1, 0, 0, 0, 0, 0, 0]
// 同理:
dataview.setUint16(0, 258);
// uint16 = [258, ...]; [0000000100000002, ...]
// uint8 = [1, 2, ...]; [00000001, 00000002, ...]
dataview.setUint16(0, 514);
// uint16 = [515, ...]; [0000001000000011, ...]
// uint8 = [2, 3, ...]; [00000010, 00000011, ...]| combined | left | right |
|---|---|---|
| 257 | 1 | 1 |
| 258 | 1 | 2 |
| 259 | 1 | 3 |
| 515 | 2 | 3 |
| 516 | 2 | 4 |
| 517 | 2 | 5 |
可以推演出:
const combined = ((2**8)**byteLength)*left + right;但这个算法存在精度丢失问题。例如:
const buffer = new ArrayBuffer(8);
const dataview = new DataView(buffer);
const max = 2n ** (64n - 1n) - 1n; // 9223372036854775807n
dataview.setBigInt64(0, max);
const left32 = dataview.getUint32(0); // 2147483647
const right = dataview.getUint32(0); // 4294967295
const left = ((2**8)**4)*2147483647;
// 得出的值是:9223372032559809000 精度丢失
// 正确应该是:9223372032559808512n
const combined = left + right;
// 得出:9223372036854776000 精度丢失如果需要完整的 64 位的范围,可以创建 BigInt:
function getUint64BigInt(dataview, byteOffset) {
// 将 64 位的数字拆分位两个 32 位(4 字节)的部分
const left = BigInt(dataview.getUint32(byteOffset));
const right = BigInt(dataview.getUint32(byteOffset + 4));
// 将两个 32 位的值组合在一起
return 2n**32n*left + right;
}这回准确了:
const bigIntLeft = BigInt(dataview.getUint32(0)); // 2147483647n
const right = BigInt(dataview.getUint32(0)); // 4294967295n
const left = 2n**32n*2147483647n;
// 9223372032559808512n 正确
const combined = left + right;
// 9223372036854775807n 正确但这个算法涉及到 BigInt 的运算,那实在太慢了。这里可以利用一下位运算符:
function getUint64BigInt(dataview, byteOffset) {
// 将 64 位的数字拆分位两个 32 位(4 字节)的部分
const left = BigInt(dataview.getUint32(byteOffset) >>> 0);
const right = BigInt(dataview.getUint32(byteOffset + 4) >>> 0);
// 将两个 32 位的值组合在一起并返回该值
return (left << BigInt(32)) | right;
}实现原理:
const buffer = new ArrayBuffer(8);
const dataview = new DataView(buffer);
const max = 2n ** (64n - 1n) - 1n; // 9223372036854775807n
dataview.setBigInt64(0, max);
const left32 = dataview.getUint32(0); // 2147483647
const formatLeft = left32 >>> 0; // 2147483647
const bigIntLeft = BigInt(formatLeft); // 2147483647n
const right32 = dataview.getUint32(4); // 4294967295
const formatRight = right32 >>> 0; // 4294967295
const right = BigInt(right); // 4294967295n
const left = (bigIntLeft << BigInt(32)); // 9223372032559808512n
const combined = left | right; // 9223372036854775807n音视频二进制数据的读取
从上面的内容可以看到使用 DataView 已经能够比较方便地进行二进制数据的读写了。但也仅包含了 8、16、32、64 位(1、2、4、8 字节)的读写,其它位的操作还得经过运算。在多媒体协议解析中 3、5、7 字节(24、30、56 位)的读取非常常见。那如何读取呢?
const buffer = new ArrayBuffer(8);
const dataview = new DataView(buffer);
dataview.setUint8(0, 1); // [1, 0, 0, 0, 0, 0, 0, 0]
dataview.setUint16(1, 2); // [1, 0, 2, 0, 0, 0, 0, 0]
dataview.setUint32(3, 3); // [1, 0, 2, 0, 0, 0, 3, 0]
// 即二进制的:
[00000001, 00000000, 00000010, 00000000, 00000000, 00000000, 00000011, 00000000]
// 十进制的:
72059793061184256| 字节数 | 二进制 | 十进制 |
|---|---|---|
| 3 字节 | 00000001 00000000 00000010 | 65538 |
| 5 字节 | 00000001 00000000 00000010 00000000 00000000 | 4295098368 |
| 6 字节 | 00000001 00000000 00000010 00000000 00000000 00000000 | 1099545182208 |
| 7 字节 | 00000001 00000000 00000010 00000000 00000000 00000000 00000011 | 281483566645251 |
读取奇数长度字节数据
来看看 3、5、6、7 字节数据如何读取,即实现:
getUint24(offset);
getUint30(offset);
getUint48(offset);
getUint56(offset);取 3 字节:
DataView.prototype.getUint24 = function(offset) {
return (this.getUint16(offset) << 8) + this.getUint8(offset + 2);
}实现原理:以 offset=0 为例
- 取出前 2 个字节:
- 执行:
const twoByte = dataview.getUint16(offset) - 结果:
00000001 00000000
- 执行:
- 右移位 8 位:
- 执行:
const left = twoByte << 8 - 结果:
00000001 00000000 00000000
- 执行:
- 取出第 3 个字节:
- 执行:
const right = dataview.getUint8(2) - 结果:
00000010
- 执行:
- 将两者相加():
- 执行:
const combined = left + right - 结果:
00000001 00000000 00000010
- 执行:
取大于 4 字节的数据时,由于 Javascript 中位运算仅支持 32 位以内,因此上面的公式已不再适用。
还记得之前在实现 64 位整数值的公式 const combined = left*((2**8)**byteLength) + right; 吗?可以使用它来实现:以 offset=0 为例
(dataview.getUint32(0) * ((2 ** 8) ** 1)) + dataview.getUint8(4) // 5 字节
(dataview.getUint32(0) * ((2 ** 8) ** 2)) + dataview.getUint16(4) // 6 字节
(dataview.getUint32(0) * ((2 ** 8) ** 3)) + dataview.getUint24(4) // 7 字节即:前四位数字 * ((2 ** 8) ** 偏差值)) + 后偏差位数字
function getByte(byteLength, offset) {
switch (byteLength) {
case 1:
return dataview.getUint8(offset);
case 2:
return dataview.getUint16(offset);
case 3:
return dataview.getUint24(offset);
case 4:
return dataview.getUint32(offset);
}
}
function getByteMoreThan4(byteLength) {
const maxBytes = 4;
const deviationLength = byteLength - maxBytes;
const prefix = dataview.getUint32(offset);
const maximum = (256 ** deviationLength);
const left = prefix * maximum;
const right = getByte(deviationLength, offset + maxBytes);
const combined = left + right;
return combined;
}来看看其计算过程:
// 获取前 4 个字节:
const prefix = 16777728; // 00000001 00000000 00000010 00000000二进制:
| 字节数 | deviationLength | maximum | left | right | combined |
|---|---|---|---|---|---|
| 5 | 1 | 00000001 00000000 | 00000001 00000000 00000010 00000000 00000000 | 00000000 | 00000001 00000000 00000010 00000000 00000000 |
| 6 | 2 | 00000001 00000000 00000000 | 00000001 00000000 00000010 00000000 00000000 00000000 | 00000000 00000000 | 00000001 00000000 00000010 00000000 00000000 00000000 |
| 7 | 3 | 00000001 00000000 00000000 00000000 | 00000001 00000000 00000010 00000000 00000000 00000000 00000000 | 00000000 00000000 00000011 | 00000001 00000000 00000010 00000000 00000000 00000000 00000011 |
十进制:
| 字节数 | deviationLength | maximum | left | right | combined |
|---|---|---|---|---|---|
| 5 | 1 | 256 | 4295098368 | 0 | 4295098368 |
| 6 | 2 | 65536 | 1099545182208 | 0 | 1099545182208 |
| 7 | 3 | 16777216 | 281483566645248 | 3 | 281483566645251 |
把多种字节长度的获取封装一下:
class ByteBuffer {
constructor(buffer, offset, length) {
this.dataview = new DataView(buffer);
this.start = this.offset = offset || this.dataview.byteOffset;
this.end = length ? this.start + length : this.dataview.byteLength;
}
read(byteLength) {
const offset = this.offset;
this.offset += byteLength;
const dataview = this.dataview;
const getUint24 = function(offset) {
return (dataview.getUint16(offset) << 8) + dataview.getUint8(offset + 2);
}
const getByte = function (byteLength, offset) {
switch (byteLength) {
case 1:
return dataview.getUint8(offset);
case 2:
return dataview.getUint16(offset);
case 3:
return getUint24(offset);
case 4:
return dataview.getUint32(offset);
}
}
const getByteMoreThan4 = function(byteLength, offset) {
const maxBytes = 4;
const deviationLength = byteLength - maxBytes;
const prefix = dataview.getUint32(offset);
const maximum = (256 ** deviationLength);
const left = prefix * maximum;
const right = getByte(deviationLength, offset + maxBytes);
return left + right;
}
return 4 >= byteLength ? getByte(byteLength, offset) : getByteMoreThan4(byteLength, offset);
}
}从左到右按位读取数据
除了 byte 的读写,bit 级的数据读取在音视频领域也很常见。在 Javascript 中针对 bit 数据并没有提供类似 DataView 这样的工具类,但我们可以自己封装一个,实现按位读取的能力:
const bitBuffer = new BitBuffer(141, 8); // 即 0b10001101
bitBuffer.read(1); // 1 = 0b1
bitBuffer.read(2); // 0 = 0b00
bitBuffer.read(5); // 13 = 0b01101最简单的实现方式就是字符串截取后再进行数字类型转换:
class BitBuffer {
constructor(num) {
this.num = num;
this.offset = 0;
}
read(readLength) {
const result = this.num.toString(2).slice(this.offset, this.offset + readLength);
this.offset += readLength;
return Number(`0b${result}`);
}
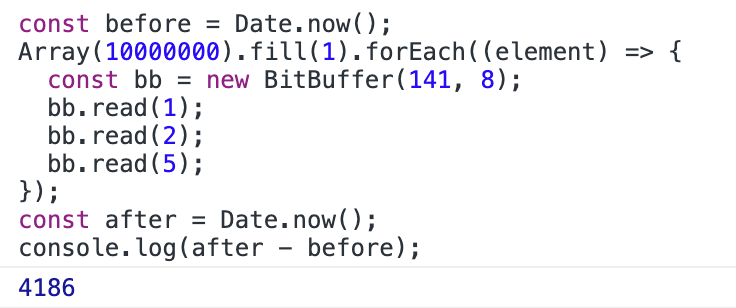
}但这种方式性能非常低,将该算法执行 1 千万次需要 4 秒:
我们可以使用位运算来实现同样的能力:
class BitBuffer {
constructor(num, length) {
this.num = num;
this.length = length;
this.offset = 0;
}
read(readLength) {
const startPos = this.length - this.offset - readLength;
if (startPos >= 0) {
let largestNumOfBit = 0;
for (let i = 0; i < readLength; i++) {
largestNumOfBit += 1 << i; // 即 largestNumOfBit + (1 << i)
}
this.offset += readLength;
return (this.num >>> startPos) & largestNumOfBit;
} else {
throw RangeError('读取位数超过限制');
}
}
}从示例的计算过程可以理解该算法的实现原理:通过右移运算获取从左到右的最小位数,然后使用与运算截取想要的位数。
| readLength | offset | startPos | num >>> startPos | largestNumOfBit | result |
|---|---|---|---|---|---|
| 1 | 0 | 7 | 0b1 | 0b1 | 1 |
| 2 | 1 | 5 | 0b100 | 0b11 | 0 |
| 5 | 3 | 0 | 0b10001101 | 0b11111 | 13 |
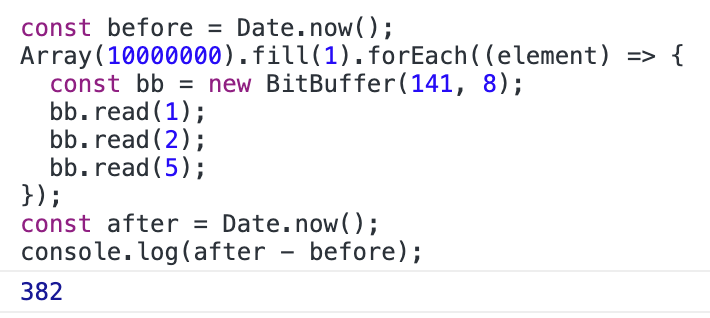
经过优化后的算法执行 1 千万次同样的操作只需要 0.4 秒,速度提升了 10 倍:
当然可能还有更高效的算法,欢迎大家探讨。
实际应用
在实现播放器的过程中,需要探测视频流来决定使用哪个解封装算法。例如探测是否是 FLV 流就需要对二进制数据进行读取:
class FLVDemuxer {
static probe(buffer) {
// ....
}
}FLV 格式主要由 FLV header 和 FLV body 两部分构成。header 部分长度为 9 个字节,前面 3 个字节为固定”FLV”拼写;第 4 个字节为版本号;第 5 个字节里第 6 位表示 audio tag,第 8 位表示 video tag。那么如何获取这些信息呢?
function probe(uint8array) {
if (uint8.byteLength < 9) {
return false;
}
const byteBuffer = new ByteBuffer(uint8array.buffer, uint8array.byteOffset, uint8array.byteLength);
const signature = String.fromCharCode(byte.read(1), byte.read(1), byte.read(1));
const version = byte.read(1);
const flags = byte.read(1);
const bit = new BitBuffer(flags, 8);
bit.read(5); // 跳过 5 位
const hasAudio = !!bit.read(1); // 读的是第 6 位
bit.read(1); // 跳过 1 位
const hasVideo = !!bit.read(1); // 读的是第 8 位
return signature === 'FLV';
}参考资料
- 现代 JavaScript 教程 - 数据类型 - 数字类型
- 现代 JavaScript 教程 - 杂项 - BigInt
- Web 开发技术 - JavaScript 指南 - 表达式与运算符
- 2-补码表示法
- 在线进制转换器
- 在线2-补码转换器
题图来源:What Enterprises Must Learn from Big Data and Data Science Revolution?