一份关于问答系统的小结

一部问答系统发展史就是一部人工智能史。伴随着人工智能的兴衰,问答系统也经历了半个多世纪的浮沉,直到今天仍然方兴未艾。笔者近期一直在从事对话式智能助手的研发(ABot ),因此对问答系统的历史、现状、学术界的研究方向及业界的解决方案有持续 follow,本文即是对该方向输入的一番整理。希望对从事「类聊天机器人」领域的同仁有所帮助。
本文主要以概述方法论为主,不涉及到算法和具体的编程实现。
问答系统简介
问答系统(Question Answering System,QA System)是用来回答人提出的自然语言问题的系统。从狭义上来说,问答系统是聊天机器人的其中一个组成部分(图 1)。
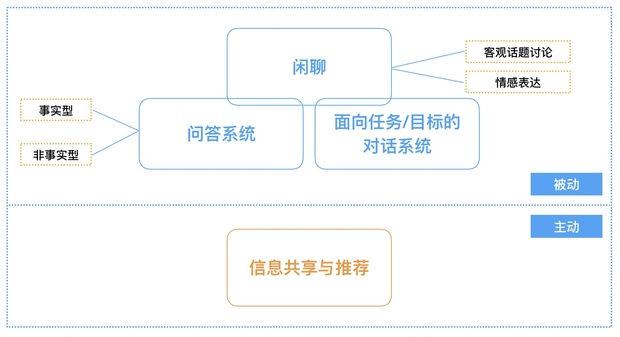
图 1:聊天机器人的分类
按照知识领域,可以将问答系统分类为“具体领域”以及“开放领域”。具体领域系统专注于回答特定领域的问题,如医药、体育、政府事务等。开放领域系统则希望不设限问题的内容范围,天文地理无所不问。
按照问题类型,又可作如下划分:
- 事实型问题:WH 问题,例如 when / who / where 等;
- 是非型问题:Is Beijing the capital of China?
- 对比型问题:Which city is larger, Shanghai or Beijing?
- 观点型问题:What is Chinese opinion about Donald Trump?
- 原因/结果型问题:how / why / what 等。
是非型和对比型这类客观问题以 事实型问题 为核心(对于是非型问题 Is Beijing the capital of China? ,事实型问题 What is the capital of China? 是其回答的基础。对于对比型问题 Which city is larger, Shanghai or Beijing? ,事实型问题 How large is Shanghai? 和 How large is Beijing? 是其回答的基础。),因此我们又可以简单地将问题类型分为 事实型 和 非事实型。针对两类问题类型的解决方案大相径庭。
经典方法
基于信息检索是传统问答系统的经典方法。其按照以下的流程工作(图 2):
- 问题解析:
- 处理问题:处理用户输入的自然语言问题,系统对于问题进行处理和分析,并对问题进行分类,确定问题类型;
- 生成搜索关键词:问题中的一些词不适合作为搜索关键词,另一些词的搜索权重则较高。系统需要对于用户的问题进行分析,来获得不同关键词的权重。
- 信息检索:系统使用从用户的问题中得到的关键词,对于数据库中的文档与关键词的计算匹配程度,从而获取若干个可能包含答案的候选文章,并且根据它们的相似度进行排序;
- 答案抽取:
- 段落提取:段落(paragraph)是包含答案的一个小节。问答系统与搜索引擎的区别在于用户期望其返回精确的答案,而不是一个文章或段落。为此首先要从文章中提取出可能包含答案的段落;
- 答案提取:在答案可能出现的段落被提取到以后,问答系统需要精确抽取段落中所包含的答案。这一步会用到问题分类。同时根据问题的关键词,对于段落中的词进行语义分析,最终找到最有可能是答案的字段。

图 2:基于信息检索的问答系统工作流程
基于知识图谱的问答
什么是知识图谱
- “奥巴马出生在火奴鲁鲁”
- “姚明是中国人”
- “谢霆锋的爸爸是谢贤”
这些就是一条条知识,而把大量的知识汇聚起来就成为了知识库。我们可以在 Wiki 百科、百度百科等百科全书查阅到大量的知识。然而,这些百科全书的知识组建形式是非结构化的自然语言,这样的组织方式很适合人们阅读但并不适合计算机去处理。为了方便计算机的处理和理解,我们需要更加形式化、简洁化的方式去表示知识,那就是知识图谱。
知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是三元组(SPO: Subject, Predicate, Object 分别表示主语、属性、宾语)。
三元组是一种通用表示方式,即 G=(E,R,S),其中 E={e1,e2,⋯,e|E|} 是知识库中的实体集合,共包含 |E| 种不同实体;R={r1,r2,⋯,r|E|} 是知识库中的关系集合,共包含 |R| 种不同关系;S⊆E×R×E 代表知识库中的三元组集合。
三元组的基本形式主要包括(图 3):
- 实体1 - 关系 - 实体2
- 概念 - 属性 - 属性值

图 3:三元组的基本形式(图片来自《揭开知识库问答KB-QA的面纱1·简介篇》)
实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等;属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;属性值主要指对象指定属性的值,例如中国、1988-09-08 等。每个实体用一个全局唯一确定的 ID 来标识,每个属性 - 属性值对(attribute-value pair,AVP)可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
回到最初的例子: “奥巴马出生在火奴鲁鲁” 可以用三元组表示为 (BarackObama(实体1), PlaceOfBirth(关系), Honolulu(实体2))。
什么是知识图谱问答
以知识图谱构建事实型的问答系统,也称之为 KB-QA(Knowledge Base Question Answering)。即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识图谱进行查询、推理得出答案(图 4)。对事实型问答而言,这种做法依赖知识图谱准确率比较高,同时也要求我们的知识图谱是比较大规模的,因为 KB-QA 无法给出在知识图谱之外的答案。

图 4:基于知识图谱的问答系统工作流程(图片来自中科院刘康在知识图谱与问答系统前沿技术研讨会中的报告)
主流方法
通过知识图谱为知识源回答问题时,一个问题的答案对应于知识图谱的一个子结构。所以其问答过程的核心在于将自然语言问题映射为知识图谱上的结构化查询。例如对于 图 5 中的知识图谱,图 6 展示了一些它可以回答的问题,以及对应的子结构。
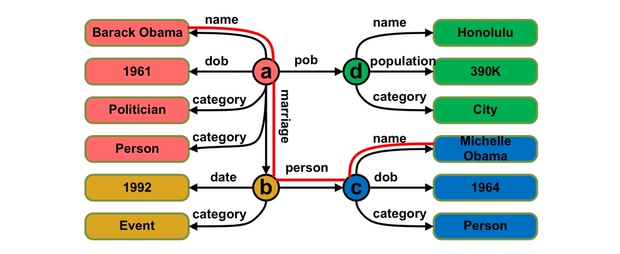
图 5:一个 RDF 知识图谱示例(图片来自崔万云的博士学位论文《基于知识图谱的问答系统关键技术研究》)

图 6:自然语言问题及其在知识图谱中的属性对应(图片来自崔万云的博士学位论文《基于知识图谱的问答系统关键技术研究》)
基于知识图谱的问答系统,需要解决两个核心问题:
- 如何理解问题语义,并用计算机可以接受的形式进行表示(问题的理解和表示);
- 以及如何将该问题表示关联到知识图谱的结构化查询中(语义关联)。
传统的主流方法可以分为三类:
-
语义解析(Semantic Parsing):该方法是一种偏语言学的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句在知识库中进行查询,从而得出答案。下图红色部分即逻辑形式,绿色部分 where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
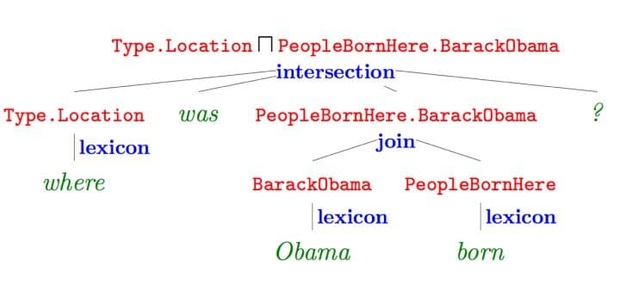
该图片来自论文:Semantic Parsing on Freebase from Question-Answer Pairs
- 信息抽取(Information Extraction):该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。
-
向量建模(Vector Modeling):该方法思想和信息抽取的思想比较接近,根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,如下图所示。模型训练完成后则可根据候选答案的向量表达和问题表达的得分进行筛选,得出最终答案。

该图片来自论文:Question answering with subgraph embeddings
基于阅读理解的问答
机器阅读理解在 NLP 领域近年来备受关注,自 2016 年 EMNLP 最佳数据集论文 SQuAD 发表后,各大企业院校都加入评测行列。利用机器阅读理解技术进行问答即是对非结构化文章进行阅读理解得到答案,又可以分成抽取式 QA 和生成式 QA。
抽取式
抽取式 QA 让用户输入若干篇非结构化文本及若干个问题,机器自动在阅读理解的基础上,在文本中自动寻找答案来回答用户的问题。抽取式 QA 的某个问题的答案肯定出现在某篇文章中。
抽取式 QA 的经典数据集是 SQuAD(斯坦福问答数据集),这是一个阅读理解数据集,由众包人员基于一系列维基百科文章的提问和对应的答案构成,其中每个问题的答案是相关文章中的文本片段或区间。SQuAD 一共有 107,785 个问题,以及配套的 536 篇文章。
SQuAD 示例:
- 内容:阿波罗计划于 1962 至 1972 年间进行,期间得到了同期的双子座计划(1962 年 - 1966 年)的支持。双子座计划为阿波罗计划成功必需的一些太空旅行技术做了铺垫。阿波罗计划使用土星系列火箭作为运载工具来发射飞船。这些火箭还被用于阿波罗应用计划,包括 1973 年到 1974 年间支持了三个载人飞行任务的空间站 Skylab,以及 1975 年和前苏联合作的联合地球轨道任务阿波罗联盟测试计划。
- 问题:哪一个空间站于 1973 到 1974 年间承载了三项载人飞行任务?
- 答案:Skylab 空间站
基于机器阅读理解模型的问答流程如下图所示:
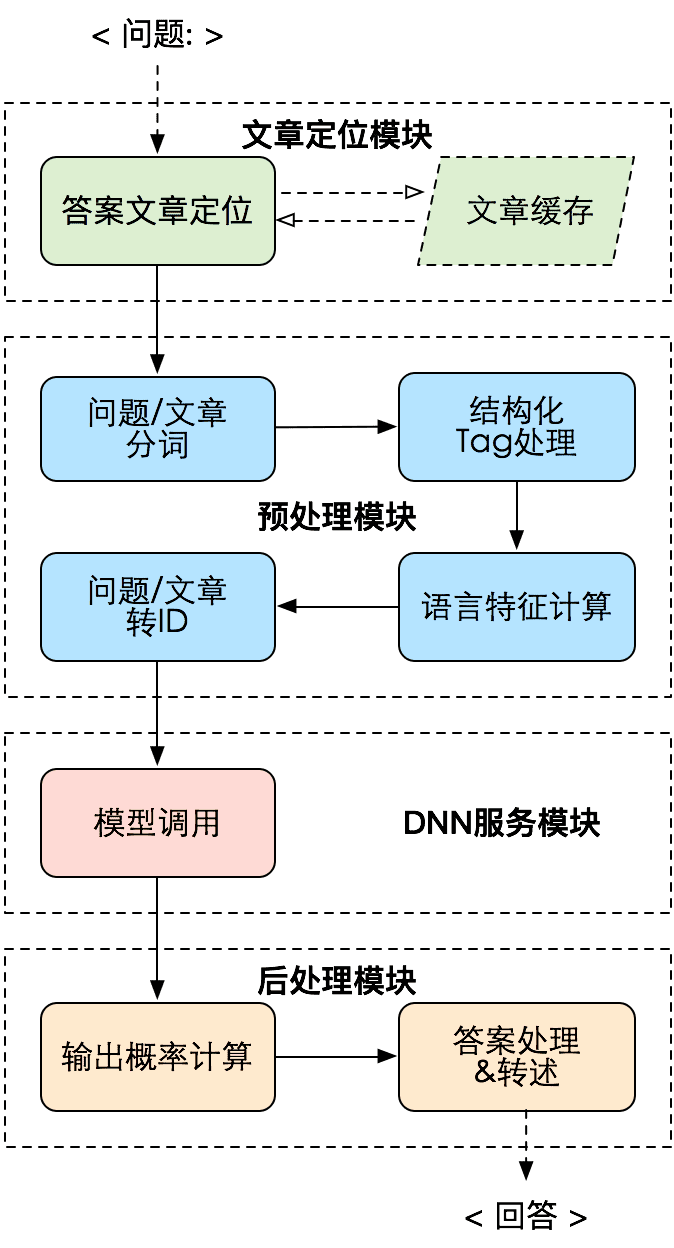
该图片来自阿里小蜜团队吉仁的文章《阿里小蜜机器阅读理解技术探索与实践》
生成式
与抽取式 QA 的问题答案来自一篇文章的某个词语、句子不同,生成式 QA 答案形式是这样的:
- 答案完全在某篇原文;
- 答案分别出现在多篇文章中;
- 答案一部分出现在原文,一部分出现在问题中;
- 答案的一部分出现在原文,另一部分是生成的新词;
- 答案完全不在原文出现(Yes / No 类型)。
目前比较好的数据集有 MSRA 的 MS MARCO 。针对这个数据集,国内的百度和猿题库都给出了自己的评测。
目前笔者在这一块的了解不多,持续关注中。
总结
- 问答系统历史悠久,相关的解决方案有很多,就本文列举的来说,每一个小节深入下去都可以再展开一个篇幅;
- 工业届的问答系统往往不是单点的方法,而是针对不同业务场景的多个方法的组合。
封面图由 Kevin Bhagat 发表在 Unsplash